


Busigence is a Decision Intelligence Company. We create decision intelligence products for real people by combining data, technology, business, and behavior enabling strengthened decisions.
Scaling established startup by IIT alumnus innovating & disrupting marketing domain through artificial intelligence. We bring those people onboard who are dedicated to deliver wisdom to humanity by solving the world’s most pressing problems differently thereby significantly impacting thousands of souls, everyday.
We try real hard to hire fun loving crazy folks who are driven by more than a paycheck. You shall be working with creamiest talent on extremely challenging problems at most happening workplace


Clients
Awards
Algorithms
Books
Each team at Busigence features its own unique blend of passion, personality, and panache. Pick the one that most feels like own. Choose your fun!
ENGINEERING | SCIENCES | DESIGN | RESEARCH | KNOWLEDGE
ENGAGEMENT | DELIVERY | OPERATIONS | ORGANIZATION | STRATEGY
Problem solving is an art and we are passionate about it
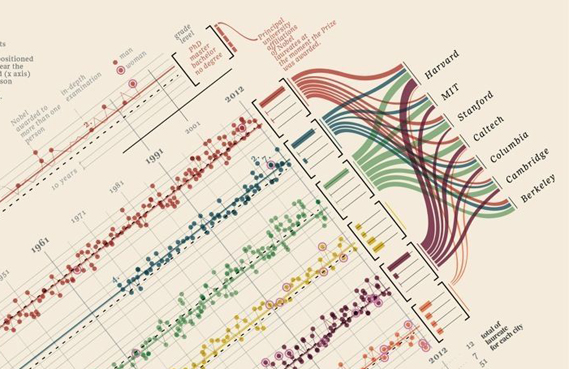
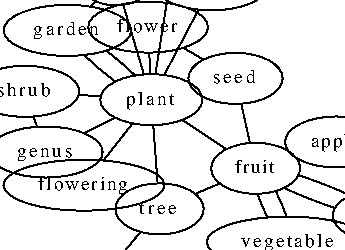
Semantic similarity between words/phrases plays vital role in natural language processing, information retrieval, and artificial intelligence. This is calculated using information from a structured lexical database and from corpus statistics.

Consumer product items being collectively analysed and linked across fifteen operational sources. Post curation, semantic relevance was calculated using machine learning algorithms like decision tree & support vector machines. Blocking algorithms implemented to scale it.

Improving Apriori algorithm by not getting candidates generating. Hash-based technique can reduce the size of candidate itemsets. Each itemset is hashed into a corresponding bucket by using an appropriate hash function.A bucket can contain different itemsets and it works on minimum support concept.
Requirement analysis on different type of music listeners, with an age group ranging from 16 to 45. The clasification includes savants, enthusiasts, casuals, indifferents, and few more. Metadata was created for editorial, cultural, & acoustic data points, followed by analsing recommendation methods.
Graph analysis includes pattern matching to find subgraphs of interest, and graph algorithms such as PageRank and triangle counting. Apache Spark is used to distribute Graph analysis. GraphFrames support general graph processing, similar to Apache Spark’s GraphX library.

Missing data needs to be handled during data exploration phase. Prediction model is one of the sophisticated method for handling missing data. We may have many new observations that have missing values on the independant variables, s random forest model was used to impute missing values.
This is for (only!) those who have been facing sleepless nights worying about The Right Start
We are building golden teams leading disruption. Experience The Real Work with The Real People for The Real Purpose
We prefer e-mail over phone to clarify your queries
(+91) 8824 121 121
careers@busigence.com
Chicago | Bengaluru
Weekdays ours-Weekends yours



